code192 Data Integration Tool Overview
What is code192 Data Integration Tool?
Put simply Data Integration Tool was built to automate the flow of data between systems. While the term dataflow is used in a variety of contexts, we’ll use it here to mean the automated and managed flow of information between systems. This problem space has been around ever since enterprises had more than one system, where some of the systems created data and some of the systems consumed data. The problems and solution patterns that emerged have been discussed and articulated extensively. A comprehensive and readily consumed form is found in the Enterprise Integration Patterns [eip].
Some of the high-level challenges of dataflow include:
- Systems fail
-
Networks fail, disks fail, software crashes, people make mistakes.
- Data access exceeds capacity to consume
-
Sometimes a given data source can outpace some part of the processing or delivery chain - it only takes one weak-link to have an issue.
- Boundary conditions are mere suggestions
-
You will invariably get data that is too big, too small, too fast, too slow, corrupt, wrong, or in the wrong format.
- What is noise one day becomes signal the next
-
Priorities of an organization change - rapidly. Enabling new flows and changing existing ones must be fast.
- Systems evolve at different rates
-
The protocols and formats used by a given system can change anytime and often irrespective of the systems around them. Dataflow exists to connect what is essentially a massively distributed system of components that are loosely or not-at-all designed to work together.
- Compliance and security
-
Laws, regulations, and policies change. Business to business agreements change. System to system and system to user interactions must be secure, trusted, accountable.
- Continuous improvement occurs in production
-
It is often not possible to come even close to replicating production environments in the lab.
Over the years dataflow has been one of those necessary evils in an architecture. Now though there are a number of active and rapidly evolving movements making dataflow a lot more interesting and a lot more vital to the success of a given enterprise. These include things like; Service Oriented Architecture [soa], the rise of the API [api][api2], Internet of Things [iot], and Big Data [bigdata]. In addition, the level of rigor necessary for compliance, privacy, and security is constantly on the rise. Even still with all of these new concepts coming about, the patterns and needs of dataflow are still largely the same. The primary differences then are the scope of complexity, the rate of change necessary to adapt, and that at scale the edge case becomes common occurrence. Data Integration Tool is built to help tackle these modern dataflow challenges.
The core concepts of Data Integration
Data Integration Tool’s fundamental design concepts closely relate to the main ideas of Flow Based Programming [fbp]. Here are some of the main Data Integration Tool concepts and how they map to FBP:
| Data Integration Term | FBP Term | Description |
|---|---|---|
FlowFile |
Information Packet |
A FlowFile represents each object moving through the system and for each one, Data Integration keeps track of a map of key/value pair attribute strings and its associated content of zero or more bytes. |
FlowFile Processor |
Black Box |
Processors actually perform the work. In [eip] terms a processor is doing some combination of data Routing, Transformation, or Mediation between systems. Processors have access to attributes of a given FlowFile and its content stream. Processors can operate on zero or more FlowFiles in a given unit of work and either commit that work or rollback. |
Connection |
Bounded Buffer |
Connections provide the actual linkage between processors. These act as queues and allow various processes to interact at differing rates. These queues then can be prioritized dynamically and can have upper bounds on load, which enable back pressure. |
Flow Controller |
Scheduler |
The Flow Controller maintains the knowledge of how processes actually connect and manages the threads and allocations thereof which all processes use. The Flow Controller acts as the broker facilitating the exchange of FlowFiles between processors. |
Process Group |
subnet |
A Process Group is a specific set of processes and their connections, which can receive data via input ports and send data out via output ports. In this manner process groups allow creation of entirely new components simply by composition of other components. |
This design model, also similar to [seda], provides many beneficial consequences that help Data Integration to be a very effective platform for building powerful and scalable dataflows. A few of these benefits include:
-
Lends well to visual creation and management of directed graphs of processors
-
Is inherently asynchronous which allows for very high throughput and natural buffering even as processing and flow rates fluctuate
-
Provides a highly concurrent model without a developer having to worry about the typical complexities of concurrency
-
Promotes the development of cohesive and loosely coupled components which can then be reused in other contexts and promotes testable units
-
The resource constrained connections make critical functions such as back-pressure and pressure release very natural and intuitive
-
Error handling becomes as natural as the happy-path rather than a coarse grained catch-all
-
The points at which data enters and exits the system as well as how it flows through are well understood and easily tracked
Data Integration Tool Architecture
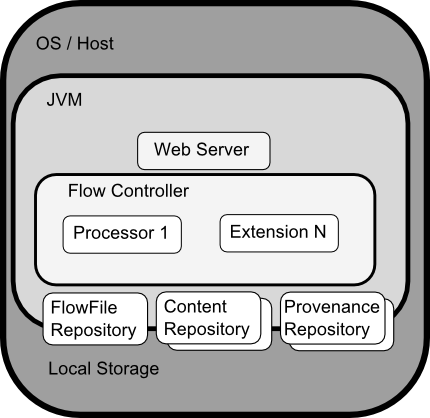
Data Integration Tool executes within a JVM living within a host operating system. The primary components of Data Integration then living within the JVM are as follows:
- Web Server
-
The purpose of the web server is to host Data Integration Tool’s HTTP-based command and control API.
- Flow Controller
-
The flow controller is the brains of the operation. It provides threads for extensions to run on and manages their schedule of when they’ll receive resources to execute.
- Extensions
-
There are various types of extensions for Data Integration Tool which will be described in other documents. But the key point here is that extensions operate/execute within the JVM.
- FlowFile Repository
-
The FlowFile Repository is where Data Integration Tool keeps track of the state of what it knows about a given FlowFile that is presently active in the flow. The implementation of the repository is pluggable. The default approach is a persistent Write-Ahead Log that lives on a specified disk partition.
- Content Repository
-
The Content Repository is where the actual content bytes of a given FlowFile live. The implementation of the repository is pluggable. The default approach is a fairly simple mechanism, which stores blocks of data in the file system. More than one file system storage location can be specified so as to get different physical partitions engaged to reduce contention on any single volume.
- Provenance Repository
-
The Provenance Repository is where all provenance event data is stored. The repository construct is pluggable with the default implementation being to use one or more physical disk volumes. Within each location event data is indexed and searchable.
Performance Expectations and Characteristics of Data Integration
Data Integration Tool is designed to fully leverage the capabilities of the underlying host system it is operating on. This maximization of resources is particularly strong with regard to CPU and disk. Many more details will be provided on best practices and configuration tips in the Administration Guide.
- For IO
-
The throughput or latency one can expect to see will vary greatly on how the system is configured. Given that there are pluggable approaches to most of the major Data Integration Tool subsystems the performance will depend on the implementation. But, for something concrete and broadly applicable, let’s consider the out-of-the-box default implementations that are used. These are all persistent with guaranteed delivery and do so using local disk. So being conservative, assume roughly 50 MB/s read/write rate on modest disks or RAID volumes within a typical server. Data Integration Tool for a large class of dataflows then should be able to efficiently reach 100 or more MB/s of throughput. That is because linear growth is expected for each physical partition and content repository added to Data Integration Tool. This will bottleneck at some point on the FlowFile repository and provenance repository. We plan to provide a benchmarking/performance test template to include in the build, which will allow users to easily test their system and to identify where bottlenecks are and at which point they might become a factor. It should also make it easy for system administrators to make changes and to verify the impact.
- For CPU
-
The Flow Controller acts as the engine dictating when a particular processor will be given a thread to execute. Processors should be written to return the thread as soon as they’re done executing their task. The Flow Controller can be given a configuration value indicating how many threads there should be for the various thread pools it maintains. The ideal number of threads to use will depend on the resources of the host system in terms of numbers of cores, whether that system is running other services as well, and the nature of the processing in the flow. For typical IO heavy flows though it would be quite reasonable to set many dozens of threads to be available if not more.
- For RAM
-
Data Integration Tool lives within the JVM and is thus generally limited to the memory space it is afforded by the JVM. Garbage collection of the JVM becomes a very important factor to both restricting the total practical size the heap can be as well as how well the application will run over time.
High Level Overview of Key Data Integration Tool Features
- Guaranteed Delivery
-
A core philosophy of Data Integration Tool has been that even at very high scale, guaranteed delivery is a must. This is achieved through effective use of a purpose-built persistent write-ahead log and content repository. Together they are designed in such a way as to allow for very high transaction rates, effective load-spreading, copy-on-write, and play to the strengths of traditional disk read/writes.
- Data Buffering w/ Back Pressure and Pressure Release
-
Data Integration Tool supports buffering of all queued data as well as the ability to provide back pressure as those queues reach specified limits or to age off data as it reaches a specified age (its value has perished).
- Prioritized Queuing
-
Data Integration Tool allows the setting of one or more prioritization schemes for how data is retrieved from a queue. The default is oldest first, but there are times when data should be pulled newest first, largest first, or some other custom scheme.
- Flow Specific QoS (latency v throughput, loss tolerance, etc.)
-
There are points of a dataflow where the data is absolutely critical and it is loss intolerant. There are also times when it must be processed and delivered within seconds to be of any value. Data Integration Tool enables the fine-grained flow specific configuration of these concerns.
- Data Provenance
-
Data Integration Tool automatically records, indexes, and makes available provenance data as objects flow through the system even across fan-in, fan-out, transformations, and more. This information becomes extremely critical in supporting compliance, troubleshooting, optimization, and other scenarios.
- Recovery / Recording a rolling buffer of fine-grained history
-
Data Integration Tool’s content repository is designed to act as a rolling buffer of history. Data is removed only as it ages off the content repository or as space is needed. This combined with the data provenance capability makes for an incredibly useful basis to enable click-to-content, download of content, and replay, all at a specific point in an object’s lifecycle which can even span generations.
- Visual Command and Control
-
Dataflows can become quite complex. Being able to visualize those flows and express them visually can help greatly to reduce that complexity and to identify areas that need to be simplified. Data Integration Tool enables not only the visual establishment of dataflows but it does so in real-time. Rather than being design and deploy it is much more like molding clay. If you make a change to the dataflow that change immediately takes effect. Changes are fine-grained and isolated to the affected components. You don’t need to stop an entire flow or set of flows just to make some specific modification.
- Flow Templates
-
Dataflows tend to be highly pattern oriented and while there are often many different ways to solve a problem, it helps greatly to be able to share those best practices. Templates allow subject matter experts to build and publish their flow designs and for others to benefit and collaborate on them.
- Security
-
- System to system
-
A dataflow is only as good as it is secure. Data Integration Tool at every point in a dataflow offers secure exchange through the use of protocols with encryption such as 2-way SSL. In addition Data Integration Tool enables the flow to encrypt and decrypt content and use shared-keys or other mechanisms on either side of the sender/recipient equation.
- User to system
-
Data Integration Tool enables 2-Way SSL authentication and provides pluggable authorization so that it can properly control a user’s access and at particular levels (read-only, dataflow manager, admin). If a user enters a sensitive property like a password into the flow, it is immediately encrypted server side and never again exposed on the client side even in its encrypted form.
- Designed for Extension
-
Data Integration Tool is at its core built for extension and as such it is a platform on which dataflow processes can execute and interact in a predictable and repeatable manner.
- Points of extension
-
Processors, Controller Services, Reporting Tasks, Prioritizers, Customer User Interfaces
- Classloader Isolation
-
For any component-based system, dependency nightmares can quickly occur. Data Integration Tool addresses this by providing a custom class loader model, ensuring that each extension bundle is exposed to a very limited set of dependencies. As a result, extensions can be built with little concern for whether they might conflict with another extension. References
References
- [eip] Gregor Hohpe. Enterprise Integration Patterns.Retrieved: 27 Dec 2014, from: http://www.enterpriseintegrationpatterns.com
- [soa] Wikipedia. Service Oriented Architecture. Retrieved: 27 Dec 2014, from: http://en.wikipedia.org/wiki/Service-oriented_architecture
- [api] Eric Savitz. Welcome to the API Economy. Forbes.com. Retrieved: 27 Dec 2014, from: http://www.forbes.com/sites/ciocentral/2012/08/29/welcome-to-the-api-economy/
- [api2] Adam Duvander. The rise of the API economy and consumer-led ecosystems thenextweb.com. Retrieved: 27 Dec 2014, from: http://thenextweb.com/dd/2014/03/28/api-economy/
- [iot] Wikipedia. Internet of Things. Retrieved: 27 Dec 2014, from: http://en.wikipedia.org/wiki/Internet_of_Things
- [bigdata] Wikipedia. Big Data. Retrieved: 27 Dec 2014, from: http://en.wikipedia.org/wiki/Big_data
- [fbp] Wikipedia. Flow Based Programming. Retrieved: 28 Dec 2014, from: http://en.wikipedia.org/wiki/Flow-based_programming#Concepts
- [seda] Wikipedia. SEDA: An Architecture for Highly Concurrent Server Applications. Retrieved: 28 Dec 2014, from: https://en.wikipedia.org/wiki/Staged_event-driven_architecture